Abstract
The (inter-)dental non-sibilant fricatives, consonants articulated with the tongue tip or blade against or between the front teeth, are rare among the world’s languages but, nevertheless, are present in the sound inventories of some of the most spoken languages in existence. Here we try to shed light on the reason(s) for their distribution using multiple approaches, ranging from examining large cross-linguistic databases and phylogenetic reconstructions to the analysis of speech production data and anatomical measurements of rigid oral cavity structures obtained using intraoral 3D optical scanning. With these, we don’t only confirm that dental fricatives are rare among the present-day languages, but also that they have likely been so as far back as language families can be reconstructed, and that they are rarely borrowed between languages. The experimental data from L2 English speakers seem to suggest that details of the anatomy of the anterior vocal tract may play a role in the success of their acquisition. Therefore, dental fricatives are rare speech sounds for a multitude of reasons touching upon their articulation, acoustics, and confusability with other speech sounds, including the difficulty to produce in both L1 and L2 acquisition, the difficulty to perceive in L2 and in borrowing situations, and the rarity of attested sound changes producing them. Nevertheless, their frequent loss and merging with other phonemes in language change. Moreover, our data suggest that tiny, continuous, and overlapping patterns of variation in the anatomy of the anterior oral vocal tract may help explain their instability and geographic patterning.
Introduction
The (inter-)dental non-sibilant fricatives are consonant speech sounds articulated by placing the tongue tip or blade against (or between) the front teeth (Ladefoged and Maddieson 1996). They are rare cross-linguistically and are difficult to acquire for L1 and L2 learners alike. Here we try to shed some light on these intriguing speech sounds through the use of a multi-pronged approach that combines quantitative studies of their present-day cross-linguistic distribution and of the factors that affect their evolution (including sound change and language contact), with an experimental investigation into the factors that influence their successful production (or not) by second-language speakers of English. When we contextualize dental fricatives within the existing literature, it becomes clear that they are rare for multiple substantive reasons, and that their distribution and evolution is driven by linguistic, socio-demographic, and biological factors.
This paper is structured as follows: first, we introduce the main questions that guided our research, followed by a description of the data and methods used, then we summarize the main findings (all the data, code and results are openly available), and we end with a discussion and ideas for future research.
The seven questions
What are they?
Dental and interdental non-sibilant fricatives (henceforth dental fricatives) broadly symbolized as voiceless [θ] (as in English third and method) and voiced [ð] (as in English the and mother), are a class of weak fricatives with common articulation involving the tongue tip or blade positioned in proximity to the upper front teeth. The exact placement of the tongue relative to the teeth can vary in anteriority, with the term interdental indicating a more extreme anterior placement of the tongue such that it protrudes between the upper and lower incisors (which must be slightly separated by jaw opening). This variation in exact place of articulation produces very little difference in the auditory quality of the fricative, and English is an example where speakers vary between dental and interdental productions within and across varieties (Ladefoged 1990: 343). Should narrow transcription differentiation be required, the extended IPA provides the diacritic ◌̪ (Ball, Howard, and Miller 2018) to denote interdental place of articulation. There is a wider class of (inter)dental sounds comprised of various other manners of articulation, including approximants, which have been reported in some languages in the Philippines and Western Australia (Mielke et al. 2011; Olson et al. 2010), and interdental stops, reported in some Australian languages (Ladefoged and Maddieson 1996).
Our focus here is strictly on fricatives, and we note that the sounds we consider are distinct from the sibilant dental fricatives [s ̪ z ̪ ]. (Sibilant interdental fricatives are a theoretical possibility, but it is difficult to produce comparably strong frication with an interdental posture because of the absence of a downstream obstruction like the teeth capable of generating a strong noise source). Being non-sibilant, dental fricatives generate little noise, and lack the distinctive “hiss” that sibilants possess (Ladefoged and Johnson 2010). They are also quiet and among the least perceptually salient consonants. Their overall low intensity is reflected in a spectrogram as a relatively faint, diffuse spectrum, with “no clearly dominating peak at any particular frequency region” (Jongman, Wayland, and Wong 2000), although some studies estimate that the main noise energy lies in the high-frequency band of around 6000 to 8000 Hz (Fry 1979; Strevens 1960). In English, as members of the non-sibilants (/f, v, θ, ð/), they have slightly shorter durations than the sibilants (/s, z, ʃ, ʒ/), although this tendency is dwarfed by the much larger difference in duration between the voiced and voiceless fricatives; they also have lower overall amplitudes and higher variability (across a range of measures, such as the spectral moments) than the sibilants (Maniwa et al. 2009). Whereas frication noise in sibilant fricatives is sufficient for listeners to distinguish between place of articulation, interdental (and labiodental) fricatives with more diffuse spectra are difficult to reliably distinguish, so that listeners must rely more heavily on F2 transition (Wright 2004). The voiced dental fricative /ð/ can typically be differentiated from its voiceless counterpart /θ/ by the presence of glottal pulses, which manifest in the spectrogram as a series of vertical striations. In addition, /ð/ also tends to be characterized by the existence of a “voice bar”, a dark band of low frequency energy near the baseline of the spectrogram (Ladefoged and Johnson 2010). Figure 1 shows a spectrogram illustrating canonical English [ð] and [θ].

What is their current cross-linguistic distribution?
The dental fricative phonemes /θ/ and /ð/ are reported to be rare among the world’s languages (Maddieson 1984; Moran and McCloy 2019), but can we quantify and describe their distribution in more detail? We approach this question using the data from the latest currently available version of PHOIBLE (Moran and McCloy 2019) and Glottolog (Hammarström et al. 2020).
Can we know if they were used in past languages?
Ascertaining the presence of speech sounds in extinct (proto-)languages is a formidable task, but even more so when they are rare. So, what can we say about the presence of dental fricatives in ancient and reconstructed languages, if anything? To answer this question, we use the data available in the latest version of the BDPROTO database (Marsico et al. 2018; Moran, Grossman, and Verkerk 2020).
How are they borrowed?
Pretty much anything can be borrowed under the right circumstances (Thomason and Kaufman 1988), but the details are very complex, indeed. So, can we say anything about the languages that borrowed dental fricatives and under what circumstances? We use the data available in the SegBo database (Grossman et al. 2020) to try to answer this question.
How are they transmitted vertically?
Besides being (possibly) borrowed, dental fricatives also evolve vertically, being inherited, lost or innovated within language families. We investigate this using phylogenetic methods (Dunn et al. 2008) applied to the PHOIBLE database (Moran and McCloy 2019) in a few large families that make the application of such methods possible, retrieved from D-PLACE (Kirby et al. 2016).
Does vocal tract anatomy influence their acquisition and production?
It is generally agreed that dental fricatives are hard to acquire for native speakers (Laitman et al. 1972) as well as for second-language learners, with several patterns of substitutions being reported and (partly) explained by orthography, perception, phonology, and phonetics. Here we analyze a large database of speakers from four large ethno-linguistic groups that are trained to produce dental fricatives, and where we try to predict their success rate at producing the intended /θ/ and /ð/ using various individual measures, including measures capturing the anatomy of the vocal tract. In effect, we are trying to see if there are aspects of the vocal tract that influence the articulation of the dental fricatives and which may help explain not only inter-individual differences in their production, but also possibly their cross-linguistic patterning.
So, why are they rare?
Finally, we hope that the (partial) answers to all of the questions above might help us explain not only why these speech sounds are rare, but also why they are distributed the way they are both between and within languages.
Data & methods
Here we briefly summarize the data and methods used, but the full data, code and results are available in the GitHub repositories bambooforest/interdentals and ScottMoisik/DentalFricGit, for the cross-linguistic and experimental approaches, respectively. Moreover, the code needed to generate this paper is available in the GitHub repository ddediu/the. We used R (R Core Team 2021) and Rmarkdown (Xie, Allaire, and Grolemund 2018) through RStudio for data analysis, plotting and the generation of the reports and of this paper.
Cross-linguistic approaches
We used the following databases: PHOIBLE (Moran and McCloy 2019) for the presence/absence of dental fricatives across the world’s languages (in particular, for θ and ð); Glottolog (Hammarström et al. 2020) for information about language families; D-PLACE (Kirby et al. 2016) for retrieving the phylogenies of large families used in the phylogenetic analyses; BDPROTO (Marsico et al. 2018) for the presence/absence of dental fricatives in ancient and reconstructed languages (selecting the phonemes “θ” and “ð”); and SegBo (Grossman et al. 2020) for data on borrowing (selecting the phonemes “θ” and “ð”). While there might be various sources of errors and biases in such databases (due to, for example, transcription traditions or the linguist’s familiarity with languages that possess dental fricatives), these are notoriously hard to spot and would need a study of their own; however, such errors and biases should not affect our conclusions here too much.
Methodologically, all analyses were implemented in R using various packages (please see the corresponding analysis report for details). For the phylogenetic analyses, we used data for the Indo-European and Sino-Tibetan language families, as published in Chang et al. (2015) and Zhang et al. (2019), respectively, and available from D-PLACE (Kirby et al. 2016). For this, we first pruned these phylogenies to the dental data available (collapsing, in the process, several varieties belonging to the same Glottocodes into a single value), and then we generated stochastic character maps (Huelsenbeck, Nielsen, and Bollback 2003; Nielsen 2002; Revell 2012) using the make.simmap() function from package phytools (Revell 2012) with the “all rates different” model (ARD), where Q is set to “empirical” (maximum probability, full Bayesian MCMC) with 10 simulations.
Experimental approach
Here we capitalize on a large dataset, part of the ArtiVarK (Articulatory variation in speech and language) project conducted at the Max Planck Institute for Psycholinguistics, in Nijmegen, The Netherlands, between 2012 and 2017 (for more details, please see Dediu and Moisik 2019). This project is covered by the ethics approval 45659.091.14 (1 June 2015), Donders Center for Brain, Cognition and Behaviour, Nijmegen; for a full description, please see the Supplementary file 1 of Dediu and Moisik (2019) hosted at doi:10.5281/zenodo.1480427. While the full dataset comprises speech data, anatomical measurements, as well as detailed language background information from 96 participants from several large ethno-linguistic groups, we keep here only the L2 English speakers (removing thus 6 native English speakers). We also removed 7 other participants that were part of a convenience sub-sample used to “fine-tune” the experimental protocol, retaining here 80 participants, all L2 English speakers with no dental fricatives in their respective L1 inventories, from four broadly defined ethno-linguistic groups: “Dutch” (speakers of Dutch from the Netherlands), “Chinese” (speakers of Sino-Tibetan languages), “North Indian” (speakers of Indo-Aryan languages), and “South Indian” (speakers of Dravidian languages). The participants were generally young (mean age 25) and had very little formal training in phonetics despite being highly educated.
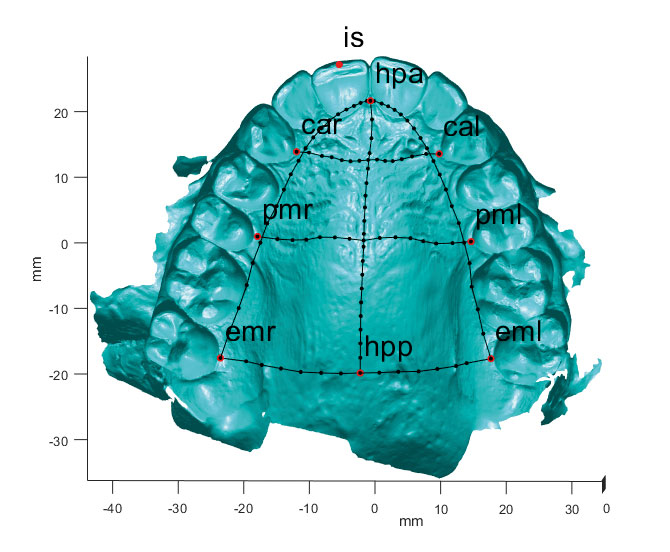
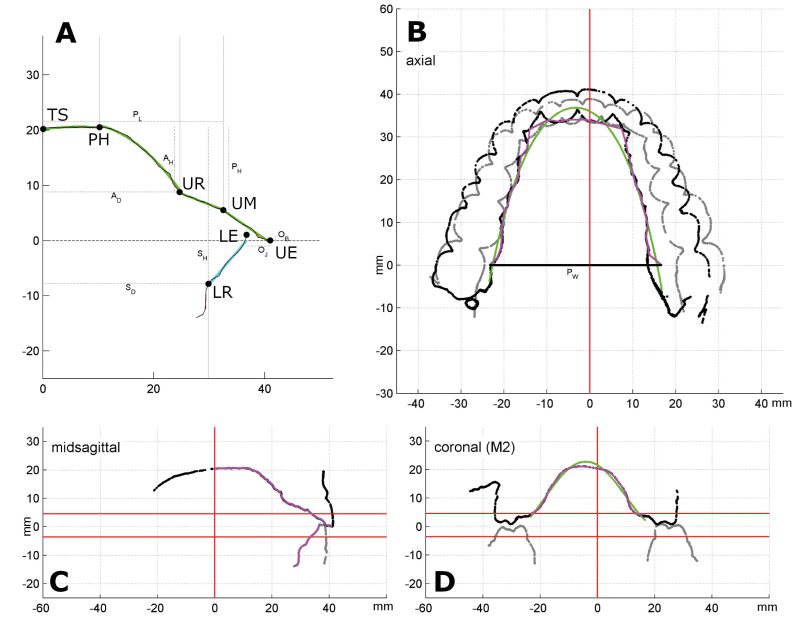
Linguistic speech data was acquired at the Donders Center for Brain, Cognition and Behaviour, Nijmegen, using: (1) an informal interview, using prompts such as “What other languages do you speak?” and “Tell me a little bit about your experience learning English; when were you first exposed, when was it formally introduced in school, and so forth,” for the purposes of eliciting naturalistic speech; and (2) a formal reading task, where participants were instructed to produce various sounds in an isolated /a_a/ context, a sentence context “I say /a_a/ for them”, and a tongue twister context, e.g. “This thin thought”. Anatomical data was obtained through high resolution intraoral 3D optical scans using a TRIOS® 3shape system at the Department of Orthodontics and Craniofacial Biology, UMC Radboud, Nijmegen. In order to quantify these anatomical data, the intraoral scans were landmarked and traced using Landmark (Wiley 2007) and aligned and analyzed using a custom MATLAB script see Figure 2. The landmarks and measures were chosen to provide a reasonable coverage of features of the upper and lower jaws that might theoretically impact the articulation of dental fricatives (among other sounds that were part of the original ArtiVarK study (Dediu, Janssen, and Moisik 2019; Dediu and Moisik 2019). After eliminating anatomical variables that were too strongly inter-correlated (see Dediu and Moisik 2019) and adding the Principal Components (PCs) of overall jaw morphology obtained from the Principal Component Analysis (PCA) of the vertex data from the intraoral scans (see Dediu et al. 2019), a final total of 34 anatomical variables characterizing the various rigid structures of the vocal tract were retained (see Figure 3 and the Appendix; these anatomical data can be found in the supplementary materials of Dediu and Moisik (2019), freely available at doi:10.5281/zenodo.1481941). Given the high inter-correlations between some of the anatomical variables, we also ran a Principal Component Analysis across all these variables, resulting in a set of Principal Components that capture the same variation but are statistically independent. Participant sex, age, height, weight, formal phonetic experience, self-declared English proficiency and the broad ethno-linguistic group were also included. All independent variables were standardized (z-scored).
From the acoustic recording, all tokens of dental fricatives were transcribed and coded auditorily, and on the basis of the acoustic signal and spectrogram using Praat (Boersma and Weenink 2001). As noted in previous studies, it is extremely difficult to annotate dental fricatives with absolute certainty: it is challenging to identify dental fricatives reliably from spectrograms, and even trained phoneticians tend to disagree on what classification should be used where dental fricatives are concerned (Moorthy and Deterding 2000). Therefore, a broad transcription was used as far as possible, i.e., diacritics (such as aspiration) were avoided unless required, to increase inter-rater reliability, but at the same time keeping in mind that most of these dental fricative judgments remain subjective (particularly in the case of voiced dental fricatives). Two raters coded the data as follows: the first rater (LJ) performed a transcription and segmentation of the data using Praat and a custom tool developed in MATLAB, while the second rater (SRM) provided an auditory judgment (assisted only by a waveform visualization) of whether, for each case of dental fricative transcribed by the first rater, the production could be considered successful (i.e., whether it was produced as the intended voiceless or voiced non-sibilant dental fricative or something else); θ and ð were examined separately. For each token, there were 4 tiers of labeling: segment (what was actually produced by the participant), target (what the correct production should have been), position (word position of the dental fricative; initial, medial, or final), and word (the word that the dental fricative occurred in); the latter two are ignored here due to the low number of occurrences of certain values (e.g., dental fricatives in word-final position). This allows us to observe the various patterns of productions or substitutions that are being used, and to determine the “success rate” for each participant (how often the participant accurately produced the intended dental fricative). In the statistical analyses, we used the second-pass coding.
Given the exploratory nature of this paper and the relatively small sample size, we ran three broad types of statistical analyses, but all implemented as mixed-effects (also known as hierarchical) logistic regression whereby the dependent variable (the DV) is the binary success (“yes” if the second-pass coding of the token matches the intended dental fricative, otherwise “no”), the fixed effects (or predictors or independent variables, IVs) depend on the model tested, and the participants are modeled as a random effect. The three broad types are: (1) the independent contribution of each possible IV to predicting the DV, (2) the overall contribution of those IVs that capture aspects of the anatomy of the vocal tract (henceforth anatomical IVs or aIVs) to predicting the DV above and beyond the non-anatomical IVs, and (3) step-wise statistical model simplification, where we start with the full model containing all the possible IVs and remove sequentially those IVs that are either too inter-correlated with the other IVs or do not make a sufficiently important contribution to predicting the DV, ending with a reduced model with uncorrelated IVs that each contribute to predicting the DV. Each of these was implemented using both frequentist and Bayesian approaches, as follows. The frequentist approach used function glmer(..., family=binomial(link="logit")) in library lme4 (Bates, Mächler, Bolker, and Walker 2015), with fixed-effect p-values as given by the asymptotic Wald tests or model comparison through anova() with a χ2 test; we used throughout an α-level of 0.05. The Bayesian approach used function brm(..., family=bernoulli(link="logit")) in library brms (Bürkner 2021) with a student_t(3, 0, 3) prior for all fixed effects; we used visual checks and R ̂ for model convergence, visual checks of the posterior distributions, and the practical equivalence test, ROPE-based p-values, and posterior null hypothesis testing (as implemented by the functions equivalence_test() and p_rope() in library bayestestR and the function hypothesis() in library brms, respectively); we also used model comparison with Bayes factors, LOO, WAIC and K-FOLD (n=10). For both approaches to model simplification, we first used VIF (Variable Inflation Factor) with a cut-off of 5 to sequentially remove the highly correlated IVs (i.e., at each step the IV with the highest VIF would be removed until all remaining IVs had a VIF < 5), but while we used the actual mixed-effect logistic model in the frequentist approach to estimate the VIFs, we used instead a “flat” linear model with a randomly generated normal (N(0,1)) “fake” DV (as suggested by the creator of the brms package, Paul-Christian Bürkner; this is based on the fact that the VIF of a predictor depends only on the other predictors and not on the dependent variable, in essence being a programming “trick” to use R’s check_collinearity() function from package performance). This was followed by the “importance”-based sequential removal of IVs, in the frequentist approach using the AIC (Akaike Information Criterion)-based method implemented by R’s step() function, followed by a p-value-based method; in the Bayesian approach, we used the practical equivalence test, ROPE-based p-values, and posterior null hypothesis testing, ranked in this order. We also performed a post-hoc statistical power analysis to study the effect of sample size on the probability of detecting the kind of anatomical effects on the success rate of θ and ð observed in our data.
It is important to stress that we interpreted the results of these approaches jointly, trying to extract the strongest signals in our data, and that we see these results as purely exploratory and we intend them as generating hypotheses for future, targeted studies.
Results
The results are structured by question (except for the first question, which was already answered above), but the interested reader can find full details in the two GitHub repositories mentioned.
What is their current cross-linguistic distribution?
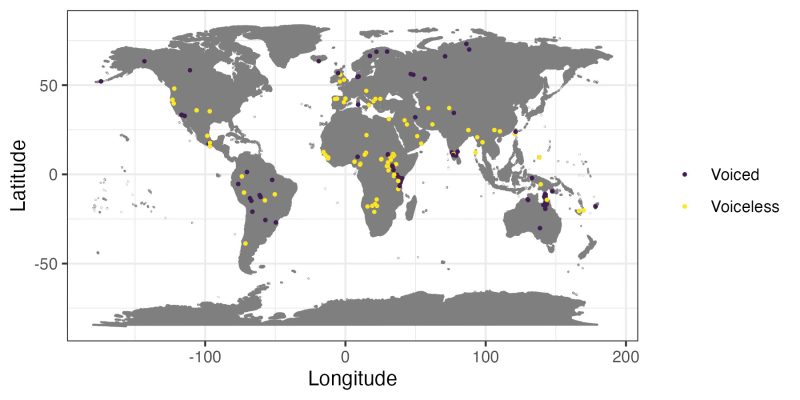
There are currently 2177 distinct Glottolog codes in PHOIBLE, of which 220 (or 10.1%, representing 237 inventories) have dental fricatives. Also considering various diacritics and combinations, the dental fricatives appearing in more than two inventories are: ð (160; 67.5%), θ (123; 51.9%), ð ̞ (7; 3%), ð ̪̺ (6; 2.5%), t̪ θ (5; 2.1%), t̪ θʼ (5; 2.1%), ðː (4; 1.7%), ðj (4; 1.7%), t̪ θh (4; 1.7%), d ̪ ð (3; 1.3%), ðʕ (2; 0.8%), and θ̪ (2; 0.8%). It is clear that the overwhelming majority is represented by θ and ð.
They are attested in all macroareas: Africa (76), Australia (28), Eurasia (67), North America (21), South America (15) and Papunesia (12), but most inventories have only one dental fricative (152 representing 64.1%), while 72 (30.4%) have 2, 9 (3.8%) have 3, 1 (0.4%) has 4, and 3 (1.3%) have 5. There are slightly more inventories with a voiceless than with a voiced dental fricative (Fig. 4).
Can we know if they were used in past languages?
There are 214 unique Glottolog codes in BDPROTO, of which 24 have dental fricatives (11.2%). The most frequent dental fricatives are [ð] (21 occurrences) and [θ] (15), followed by [θ̪] (6), [ð ̪ j] (5), [θː] (4), [ðː] (2), [θʼ] (2), [θʕ] (2) and several more with a single occurrence, but these estimates should be taken as suggestive at best. Recent work also shows that the relative frequency of dental fricatives in languages today (as given by PHOIBLE) is lower than what it was in the past (as given by BDPROTO), whereas, for example, the labiodental fricatives show the opposite trend, becoming much more common now than in the past (Moran, Lester, and Grossman 2021).
How are they borrowed?
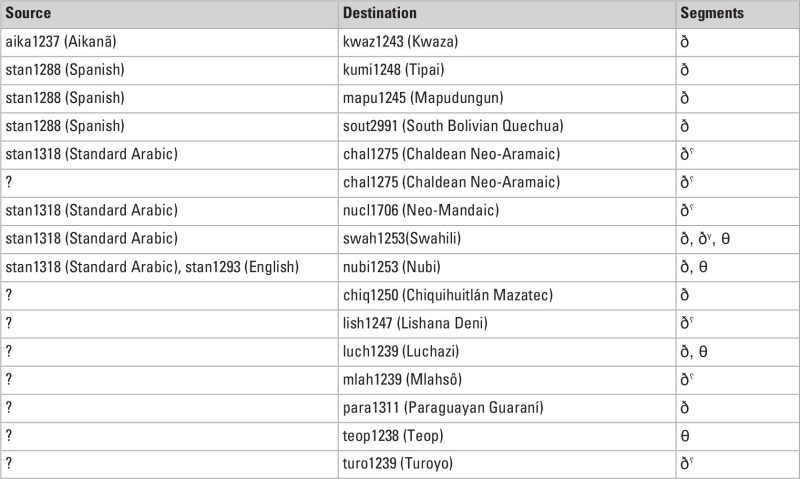
The SegBo database contains 598 datapoints, but only a handful of cases where dental fricatives were borrowed (see Table 1). It can be seen that most cases involve single segments and an unknown origin, but also that Swahili [swah1253] borrowed three dental fricatives from Standard Arabic via loanwords, as did Nubi [nubi1253] for two dental fricatives from Arabic or English. However, the rarity of these borrowings should be seen in the context of the overall rarity of dental fricatives and of the nature of SegBo, which is a convenience sample, not genealogically nor areally balanced.
How are they transmitted vertically?
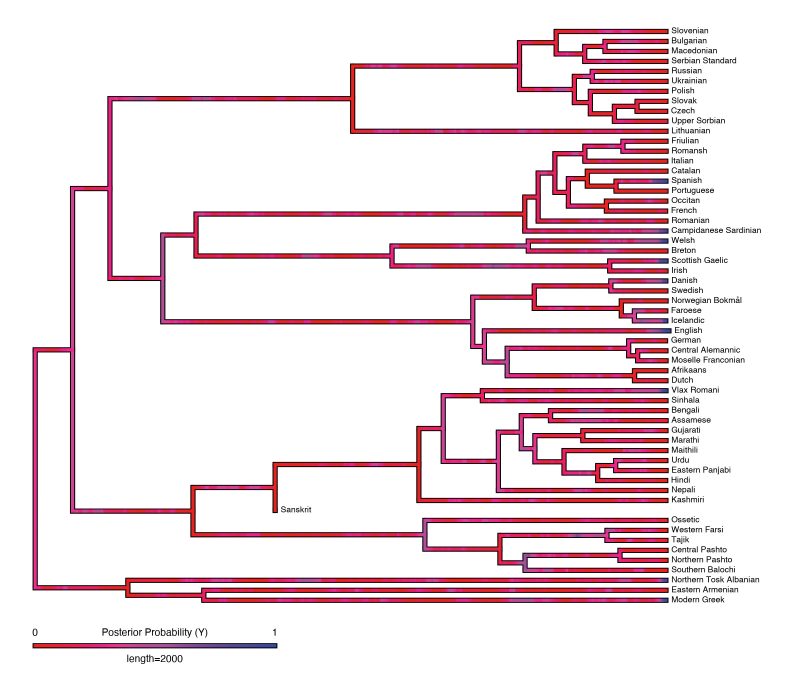
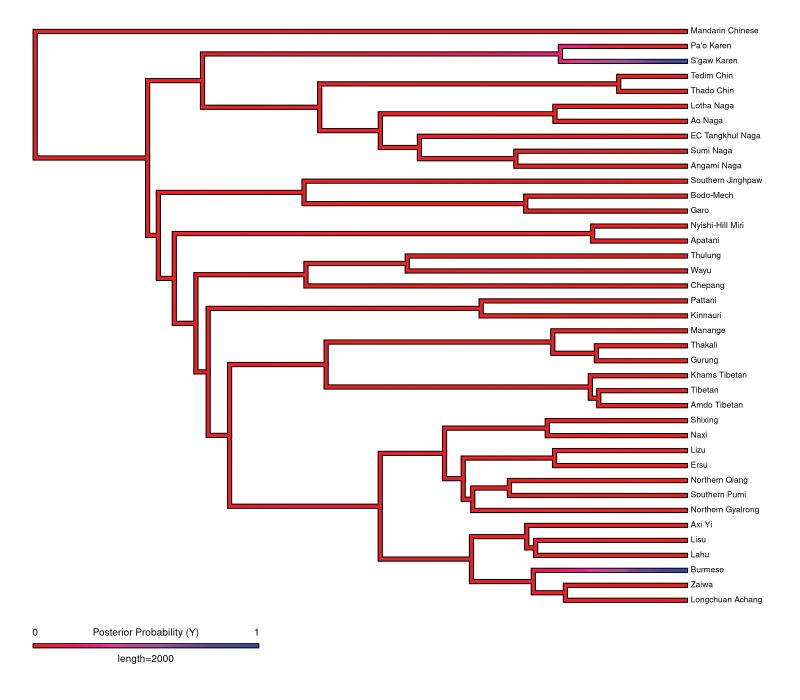
Here we use phylogenetic methods to investigate the diachronic evolution of dental fricatives, more precisely to estimate the way languages gain or lose such sounds through time, as well as the probabilities that ancient proto-languages might have had such sounds. However, such methods are fruitfully applicable only for large language families where enough languages (and, if possible, earlier proto-languages) have non-missing data for the traits of interest (here, the presence or absence of dental fricatives in their inventory). In practice, this means that we only investigated the Indo-European and the Sino-Tibetan languages (N.B. other families might be amenable to such analyses, but we leave this for future research). For Indo-European, we used the phylogeny published by Chang et al. (2015), and for Sino-Tibetan that published by Zhang et al. (2019), both available in D-PLACE (Kirby et al. 2016). Matching the available data for the presence/absence of dental fricatives in the languages of these families results in the pruned phylogenetic trees shown in Figures 5 and 6, where, for each language with data, we show if it has (blue) or does not have (red) dental fricatives. While for Indo-European there are quite a few languages with dental fricatives, for Sino-Tibetan there are only two such languages: S’gaw Karen [sgaw1245] and Burmese [nucl1310]; Burmese reportedly has dental fricatives /θ/ and /ð/, and S’gaw Karen (also spoken in Myanmar and Thailand) reportedly has a voiceless dental fricative /θ/, but more research is needed about their phonetics and history. For both families, there is an overwhelming probability that dental fricatives were not present in their proto-languages (≈80% for Indo-European and ≈95% for Sino-Tibetan), but emerged relatively recently and rather “patchy” (especially in Sino-Tibetan); see Figures 5 and 6.
Does vocal tract anatomy influence their acquisition and production?
Exploratory analyses
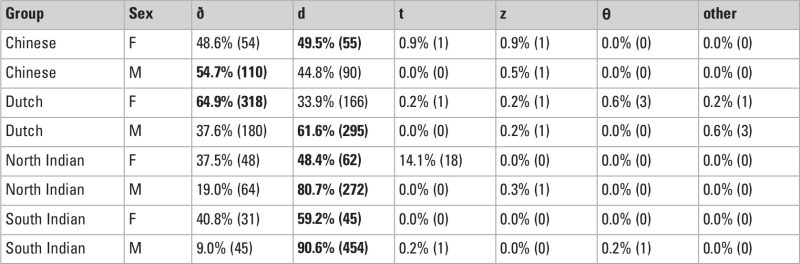
Figures 7 and 8 show the various patterns of /θ/ and /ð/ productions per participant, respectively, while Tables 2 and 3 summarize it by sex and group.


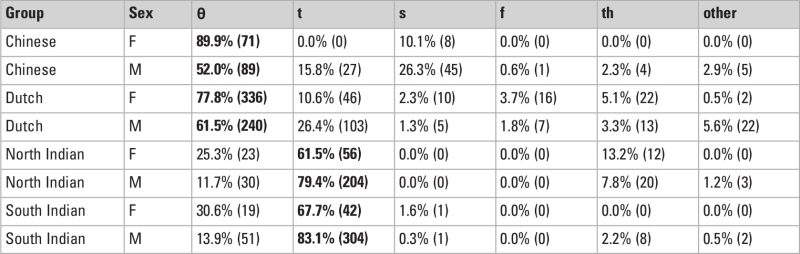
For /θ/, it can be seen that the majority of participants are able to produce [θ] to some extent, although there are a fair number of participants (mostly from the North and South Indian groups) that never produced it at all, and that many participants do not stick to using only one type of substitution. The accuracy rates differ vastly between groups: Dutch is most accurate overall (70.1%), followed by Chinese (64%), while the accuracy of the North and South Indian groups is much lower (at 15.2% and 16.4%, respectively). [t] is the most common substitution, being used to some degree across all groups, although there is a tendency for [s] substitution in the Chinese group over [t]. Females are markedly more accurate than males across all groups.
For /ð/, more than half of the participants are able to produce it as [ð] to some extent, although accuracy rates are lower than for /θ/ across the board. The Chinese and Dutch groups are accurate nearly only half the time (52.6% and 51.4%, respectively), and the North Indian and South Indian groups remain less accurate (at 24.1% and 13.2%, respectively). Females are generally more accurate than males. There is less variation in the substitutions used here, with near-unanimous usage of [d] across all groups, and minimal usage of [z], which is surprising, as it was reported to be one of the common substitutions for the Chinese group (Deterding 2006).
Principal Component Analysis
Given that some of the anatomical measures are highly inter-correlated, we also performed a Principal Component Analysis (PCA) on them. The first 13 PCs explain 90% of the variation, but there is a relatively steep drop in the explained variance after the first 4 components: PC1 explains 16.9% of the variance, PC2 15.3%, PC3 13.8%, PC4 11.1%, and PC5 only 6.6%.
Inter-rater agreement
We estimated the agreement between the two raters using: (1) the percent agreement (91.6% for [θ] and 81.3% for [ð]), (2) Cohen’s κ (0.83 for [θ] and 0.64 for [ð], both significantly different from 0), (3) Krippendorff’s α (0.83 for [θ] and 0.63 for [ð]), and (4) ICC (the intraclass correlation coefficient with only the productions as random effects but not the raters; 0.83 with 95% confidence interval [0.82,0.84] for [θ] and 0.63 with 95% CI [0.60,0.65] for [ð], both significantly different from 0). It is clear that [θ] has a much higher agreement than [ð], but both show substantial agreement (e.g., McHugh (2012) suggests 80% as the minimum for percent agreement, and that Cohen’s κ values higher than 0.6 as showing moderate agreement and values above 0.8 as having strong agreement). However, given that we used the checked scores in the actual analyses (i.e., those of the second rater), these inter-rater agreements do not have the usual interpretation, but should be taken rather as the degree of consistency between the first pass coding and the final coding.
Fitting the IVs one by one
Fitting the IVs one by one suggests that while there is quite solid evidence of anatomical influences on θ (especially in what concerns lowIA, jTotPC3, PC9 and PC10), for ð the evidence is very circumstantial; combining θ and ð suggests some anatomical effects (especially of jLowPC3). Looking at the non-anatomical factors, sex (females are significantly better), phonexp (has a positive effect) and group clearly affect performance. For the latter, there seem to be no differences between North vs South Indians, and between Dutch vs Chinese, but there are significant differences between, on the one hand, Dutch and Chinese (better performance) vs North (except not for ð) and South Indians. Also, there is a clear difference between the two sounds (θ has significantly better performance than ð).
Model comparisons
Comparing the models with and without aIVs, which test the overall contribution of those IVs capturing aspects of vocal tract anatomy, seems to suggest that vocal tract anatomy contributes to predicting success, especially clearly for [θ] and combined, but less convincing for [ð], more so when using the frequentist approach than when using the Bayesian approach.
Model simplification
Please note that all the details about the model simplifications, including the order of removing predictors and the reasons therefor, are given in the ScottMoisik/DentalFricGit GitHub repository, particularly in the HTML analysis report.
In the frequentist approach, for [θ], several aIVs predict success, in particular m2Height, C.P2w and jLowPC3 (having a negative effect, denoted henceforth as “–”), and lowIA, slMDepth and aRA (positive effect or “+”); likewise, using the Principal Components, PC7 (–) and PC3 (+) help predict success; using both types of IVs, the conditional R2 > 85%. In contrast, for [ð] the evidence is much weaker (but still concordant with that for [θ]): m2Height, C.P2w, jLowPC3 and pRoofA (–), with a conditional R2 > 82%. Combining the two sounds finds m2Height (–) and slMDepth (+), and PC7 (–) and PC3 (+), with a conditional R2 > 75%. Analyzing the four groups separately drastically reduces the power, and we applied no multiple testing correction across the groups, so these results should be taken as suggestive at best. For the Dutch, for both sounds phonexp seems to have a positive effect, for the North Indians, possibly engprof has a positive effect for [ð], for the South Indians and the Chinese, there are weak hints that vocal tract anatomy might affect both sounds.
In the Bayesian approach, for [θ], several aIVs predict success, in particular m2Height, C.P2w and jLowPC3 (–), and lowIA and slMDepth (+); PC7, PC8 and PC10 (–) and PC5 (+). For [ð] there is evidence for a negative effect of m2Height; and positive for PC11. Combining the two sounds finds effects for C.P2w (–) and slMDepth (+), and PC8 (–), and PC5 and PC11 (+), respectively. Analyzing the four groups separately: for the Dutch, for both sounds phonexp (+), and there are some hints of effects of vocal tract anatomy; for [θ], PC7 (–), for [ð], jLowPC2 (–), and for the combined sounds, slMDepth (+), jLowPC2 (–) and PC12 (–). For the North Indians, for [6theta;], engprof, weight, PC11 and PC13 (+) and pWid, m2Height, overjet, PC6, PC9 and PC10 (–); for [ð], engprof, weight, PC2 and sex (female) (+), and m2Height (–); when combining the sounds, sex (female), phonexp and PC6 (+) and m2Height, PC7, PC8 and PC13 (–). For the South Indians, there are some hints that vocal tract anatomy affects both sounds. For the Chinese, for [θ], pHLRat and antPAreaR (–), and aRA, pRoofA, sex (female), engprof, PC5 and PC8 (+); for [ð], cWidth, PC8 and PC12 (+), and lowIA, aRHeight, antPArea, antPAreaR and PC13 (–).
Power analysis
For both [θ] and [ð] we focused on the effects of C.P2w, which, in the reduced models, has an effect β of about –1.0 in both cases. The observed (post-hoc) power (for an α-level of 0.05) is 75.6% with a 95% CI (72.8%, 78.2%) for [θ], and 41.9% (38.8%, 45.0%) for [ð]. Changing the number of participants (respecting the distribution by sex and group) suggests that we would need about 85 participants to achieve a power 1–β = 80% and about 120 participants to achieve 90% for [θ], but about 220 participants and about 350 participants, respectively, for [ð].
Discussion & conclusions
Our cross-linguistic analyses seem to confirm that the dental fricatives are relatively rare among the present-day languages, being attested in only about 10% of these, spread across all macroareas. Moreover, the majority of the languages that do contain dental fricatives in their phonological inventory have only one dental fricative. Globally, there are slightly more languages with voiceless than with voiced dental fricatives. This present-day situation seems to not be very different from what can be inferred about the past, with only about 11% of ancient and reconstructed languages having such sounds in their inventory. Apparently, dental fricatives are very rarely borrowed between languages, but this has to be taken with a grain of salt given their overall rarity. When segments are typologically very common, e.g., [m, k, i], or very rare, e.g., they appear in only one or a few languages, they are less likely to be borrowed because most languages already have the segment or because the segment is rarely in a contact situation to induce borrowing (Eisen 2019). And if the results for two large language families that we could analyze phylogenetically (Indo-European and Sino-Tibetan) are to be taken at face value, then dental fricatives seem to emerge relatively seldom and to disappear quickly. These findings seem to support Nichols (2017)’s suggestion that these sounds are rare because they are ultimately prone to replacement. However, it is interesting to note that dental fricatives do occur, and have been retained in (at least in some of the dialects of) some of the languages with very large numbers of speakers (and which enjoy high prestige), including English, Castillian Spanish, and Standard Arabic.
Switching now to their acquisition and patterns of substitution, studies in both first (L1) and second (L2) language highlight that the acquisition of dental fricatives is difficult. During L1 acquisition, dental fricatives are often substituted for other speech sounds as they are difficult for children to articulate (Laitman et al. 2014). Difficulties in their production and perception are well documented in L2 acquisition as well. In particular, they are often substituted for other speech sounds: L2 speakers of English whose L1 inventory lacks these sounds, generally face difficulties enunciating them properly in English. For these speakers, dental fricatives are often realized as, or substituted with other articulatorily or perceptually similar phonemes. The alveolar (or sometimes dental) stops [t, d] are by far the most common, followed by the alveolar fricatives [s, z], and, occasionally, by the voiceless labiodental fricative [f] (see Table 4). Note that this distribution of substitution patterns roughly parallels the changes to dental fricatives that we see in varieties of English, with stops being the most common replacement (Blevins 2006: 11) alongside the occasional appearance of labiodentals (as it occurs finally in Singapore English, such as with being commonly realized as [wɪf]; see Moorthy and Deterding 2000). However, despite extensive research and a wide range of proposed explanations, the differential substitution of dental fricatives is still not fully understood.
We briefly review below several existing theories concerning the differential substitution of dental fricatives.
Orthographic influence. It has been suggested that orthography may play a role (Brannen 2002; Paradis and LaCharité 2012). Although L1 English speakers may produce a dental fricative almost intuitively when they see the ⟨th⟩ digraph, this may not necessarily be the case for speakers of other L1s. For example, ⟨th⟩ normally represents the alveolar stop /t/ in French (e.g., bibliothèque “library” /bi.bli.jɔ.ˈtɛk/), and similarly for Dutch (e.g., thema “theme” /ˈte.ma/). Accordingly, L1 speakers of these languages may have a tendency to realize the ⟨th⟩ digraph in English as [t] as well (Brannen 2002; Wester et al. 2007). One objection to this proposal is that the voiced English dental fricative is also represented by the same digraph ⟨th⟩, and yet /ð/ is hardly ever substituted with [t] (see Table 4), and this proposal is even less applicable to speakers whose L1 does not use the ⟨th⟩ digraph, such as Japanese and Russian.

Perception-based second language (L2) theories. General models of L2 speech acquisition, such as the Perceptual Assimilation Model (PAM; (Best 1994)), and the Speech Learning Model (SLM; Flege 1995), posit that “L2 phonetic segments can only be produced as accurately as they are perceived” (Flege 2003), emphasizing the correlation between perception and production. The SLM, for example, classifies L2 sounds into 3 categories: “new,” “similar,” and “identical,” with “similar” sounds being the most problematic: if learners fail to discriminate between the L2 sound from the “similar” L1 sound, they will merge the two sounds into the same phonemic category (termed “equivalence classification” (Flege 1986)), and produce them as such. Although these theories have some empirical basis (Aoyama et al. 2004; Best, McRoberts, and Goodell 2001; Flege 1986), most notably in the case of the /r/-/l/ merger in Japanese, other studies have identified an asymmetry between perception and production in the case of dental fricatives. For instance, high rates of accuracy in discrimination tasks did not necessarily equate to matching rates of accurate production (Reis 2006; Syed 2013): even when perceptual errors were made, these did not correspond with production errors. Broadly speaking, the labiodental fricative /f/ has been found to cause the greatest perceptual confusion with the voiceless dental fricative /θ/ due to their acoustic similarities (Brannen 2002; Cutler et al. 2004; Reis 2006), and thus, these two sounds should have been categorized as the same phoneme according to the SLM, but, as discussed by Hanulíková and Weber (2010), [f] is not the most common substitution among L2 English speakers, not even when /f/ exists in their L1 phoneme inventory.
Phonological approaches. There are several phonological accounts within various theoretical frameworks, including the Feature Competition Model (Hancin-Bhatt, 1994), the Underspecification Theory (Weinberger 1997), and the Auditory Distance Model (Brannen 2011), to name a few. These theories are largely generative in nature, and mainly revolve around the saliency or markedness of abstract phonological features. For example, under the Feature Competition Model, Hancin-Bhatt (1994) identified that the feature [+continuant] marks a significant number of contrasts in German and, thus, the relative prominence of this feature is calculated to be high. Consequently, speakers of German will pay particular attention to the feature [+continuant] in their perception of the English dental fricative, causing them to map it with their fricative [s] ([+continuant]), instead of [t] ([-continuant]). The problem with most of these theories is that they are multi-layered and fairly convoluted, involving complicated algorithms to determine feature prominence, functional load, auditory distance, etc. Despite this complexity, these algorithms are not widely generalizable, i.e., they work for the languages under scrutiny, but not others, which are often brushed off as shortcomings. Additionally, Picard (2002) states that one difficulty with such theories is that they often constitute an “all-or-nothing proposition,” which is problematic, as there is evidence that while certain substitutions are predominant, these substitutions are almost never exclusive (Hanulíková and Weber 2010; Rau et al. 2009; Wester et al. 2007). They also fail to account for instances where the substitution of English dental fricatives is contextually variable, i.e., different substitutions are used depending on syllable position (Wester et al. 2007).
Phonetic approaches. Research on the differential substitution of dental fricatives was, and remains, dominated by phonological theories, on the ostensible premise that phonetics cannot successfully predict the substitutions, even though it has been acknowledged that the problem itself is phonetic in nature (Altenberg and Vago 1983). While research undertaking a more phonetic-based approach is still scarce, there are a handful of studies that have diverged from the phonological viewpoint. One phonetic-based insight on the issue was put forth by Teasdale (1997), where it was hypothesized that a speaker will “choose” to substitute his dental fricatives with fricatives or stops depending on his tongue position in the production of the phoneme /s/. It was predicted that a speaker of a language using a dental [s̪ ] will tend to substitute their dental fricatives with [s] in English, whereas a speaker of a language using an alveolar [s] will substitute it with [t]. Using noise cut-off as a basis for inferring place of articulation, it was found that European French (EF), an [s] substituting language, did indeed have a more dental [s̪ ] with a cut-off at 5.6 kHz. On the other hand, Quebec French (QF), a [t] substituting language, possessed a more alveolar [s], with a considerably lower cut-off point at 4.3 kHz. The main strength of this approach is that it seems to be able to account for the classic dilemma that phonological approaches could not: the differential substitution of EF versus QF, two similar language varieties with near-identical underlying language inventories, and yet substituting dental fricatives differently. Although Teasdale’s (1997) approach has been hailed as being “much more promising” than earlier phonological approaches (Picard 2002), it is not without limitations. For example, within her own study, the hypothesis was not upheld for Japanese and Russian, and noise cut-off was not always a reliable indicator of place of articulation. Additionally, the hypothesis did not yet include languages that substitute dental fricatives with [f], such as Cantonese (Bolton and Kwok 1990).
Clearly, there appears to be no simple, straightforward answer to the question of dental fricative differential substitution in L2 speakers. Other potential confounding factors also exist, including phonetic (neighboring sounds) and stylistic (level of formality) constraints (Dickerson and Dickerson 1977), as well as age of L2 acquisition (Cornwell and Rafat 2017) and L2 proficiency (Reis 2006), that are not discussed here due to their scarcity in the literature. Therefore, the substitution of dental fricative is probably due to a combination of multiple factors, some of which might still not be studied well enough to quantify their influence: this is why we have investigated here the potential influence of details of vocal tract anatomy on inter-individual variation. This latter point is not as unexpected as it might look at first sight (Dediu, Janssen, and Moisik 2017): the articulators are usually idealized and thought of being essentially uniform across our species, even though, like anything else biological, there is extensive, normal (non-clinical) variation in nearly any aspect of the vocal tract, on an inter-individual level, and possibly even on an inter-population level. Variation in the morphology of the vocal tract can have a nuanced but appreciable impact on speech production, as several empirical studies have shown. Brunner, Fuchs, and Perrier (2009), in their study on the effect of different palate shapes on acoustic and articulatory variability, observed that speakers with flat palates had to greatly limit their articulatory variability to counteract the natural articulo-acoustic influence of palate flattening, so as to sustain the same acoustic variability as speakers with dome-shaped palates. These results demonstrate that, in order to preserve the acoustic correlates of the perception of certain sounds, speakers “specifically adapt their articulatory variability to their morphology” (Brunner et al. 2009). In another study, Moisik and Dediu (2017) set out to investigate whether the lack of a prominent alveolar ridge, which occurs more frequently among speakers of Khoisan-type languages, aids in the production of clicks. Their results indicate that having a smooth palate may provide an articulatory “bias” in the form of decreased articulatory effort and improved volume change characteristics, as compared to having a larger alveolar ridge. More recently, Dediu and Moisik (2019) also showed that the use of either “retroflexed” or “bunched” strategies by ESL speakers in producing the North American English /r/ reflects differences in bracing based on variation in the underlying anterior vocal tract anatomy, with narrower palates favoring a “bunched” configuration; although their results are largely preliminary, they do suggest an effect of anatomy. Blasi et al. (2019), building on an earlier suggestion by Hockett (1985), show that the type of “edge-to-edge” bite more frequent among populations practicing hunting and gathering (as opposed to overjet and overbite, more frequent among populations practicing agriculture) generate a negative bias against labiodental sounds (such as /f/ and /v/). While this anatomical difference is acquired during the lifespan and ultimately due to overall differences in food consistency between the two types of diets, it does suggest that details of vocal tract anatomy affect large scale cross-linguistic variation. Taken together, these studies illustrate that anatomical factors can influence speech production, whether in terms of ease of production, articulatory strategies required, or otherwise. Therefore, it is not entirely inconceivable that there could be some physical influence on the production and substitution of dental fricatives as well, considering that extreme precision is required in the production of fricatives, so much so that even “a variation of one millimeter in the position of the target […] makes a great deal of difference” (Ladefoged and Maddieson 1996).
Our data presented here seem to support such a view. Firstly, we noticed that most participants could produce dental fricatives, albeit with varying degrees of accuracy. This has two main implications: (1) their ability to produce dental fricatives underscores that it is very unlikely that the problem is purely perceptual in nature, which undermines several perceptual theories on the matter (Best 1994; Flege 1995); and (2) dental fricative production is often not “all-or-nothing”: less than half of our participants produce them 100% or 0% of the time, while everyone else falls in between. This is generally not taken into account by many existing theories and is probably true in many other cases than the dental fricatives as well. It is therefore more realistic to undertake a probabilistic approach, like in the present study.
Secondly, we observed a fair amount of intra-speaker variation with regards to the substitutions used, that is, most speakers do not use only one type of substitution (at least for /θ/), consistent with earlier descriptive studies (Hanulíková and Weber 2010; Wester et al. 2007). We note that this is especially true for speakers that primarily use [s] substitutions: it is usually accompanied by [t] substitutions. This makes it tricky for theories that try to predict the substitutions used, as the typical working assumption for these theories is that L2 English speakers use only one type of substitution exclusively.
Third, we also observed an overwhelming tendency for alveolar substitutions across all speakers, i.e., /θ/ being realized as [t] or [s], /ð/ being realized as [d] or [z]. As mentioned previously, this is peculiar, as /t/ and /s/, unlike /f/, are not known to cause much perceptual confusion with /θ/. A possible reason for this tendency will be discussed below.
Fourth, there is a clear difference between the two sounds, with /θ/ having a higher success rate than /ð/ and being more convincingly influenced by vocal tract anatomy.
Fifth, the control variables (i.e., that do not capture the vocal tract anatomy) play an important role in explaining articulatory success. When considering each predictor individually, females (sex) are significantly better, and more experience with phonetics (phonexp) helps. When it comes to the four groups, for /θ/ there seems to be a partition between (Dutch + Chinese) vs (North + South Indians), while for /ð/ the partition is less clear. However, model simplification suggests that while phonetic experience maintains its positive effect above and beyond other covariates for both sounds and in all analyses, the effect of sex (females are better) is reliably found only in the Bayesian analyses (interestingly, English proficiency, engprof, seems to have a positive effect in the frequentist models).
Finally, the variables that capture the vocal tract anatomy seem to have an effect on /θ/ but much less convincingly on /ð/. For /θ/, the frequentist and Bayesian analyses tend to agree in finding effects of m2Height (–), C.P2w (–), jLowPC3 (–), lowIA (+) and slMDepth (+), and, when using the Principal Components, of PC7 (–). For /ð/, both analyses suggest an effect of m2Height (–). Combining the two sounds finds across both analyses an effect of slMDepth (+) and possibly of m2Height (–) or C.P2w (–). Thus, overall, it seems that m2Height has a negative influence on success for both sounds, while slMDepth seems to have a positive effect on /θ/.
Although these specific anatomical variables should not be taken too literally in light of the limitations of model simplification and the correlations between the variables (in some cases probably due to developmental coupling and ontogenetic links), they do provide evidence to support a general conclusion that details of the anatomy of the anterior oral vocal tract (see Figures 9 and 10) may indeed have an impact on (particularly voiceless) dental fricative production. Such a conclusion that anatomy impacts production seems reasonable, taking into consideration that the anterior teeth play an integral part of the articulatory system and in speech production in general, particularly so in the production of dental fricatives. For instance, Narayanan, Alwan, and Haker (1995) observed that the tongue tip/blade is more or less always in contact with the lower incisors across all speakers during the production of dental fricatives. This persistent contact with the lower incisors may indicate bracing of some kind (Gick, Allen, Roewer-Després, and Stavness 2017), and it could be that having less vertical incisors may affect this “mechanical support” and, consequently, impact the successful production of a dental fricative. A labial angulation of the upper incisors, too, has been found to adversely affect the production of fricatives (Runte et al. 2001).
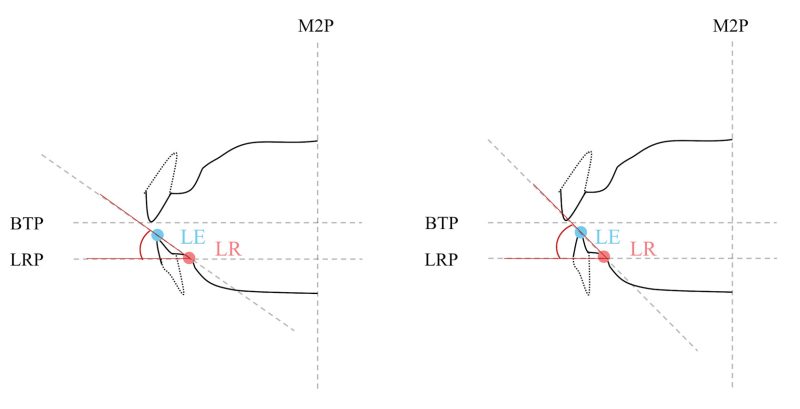
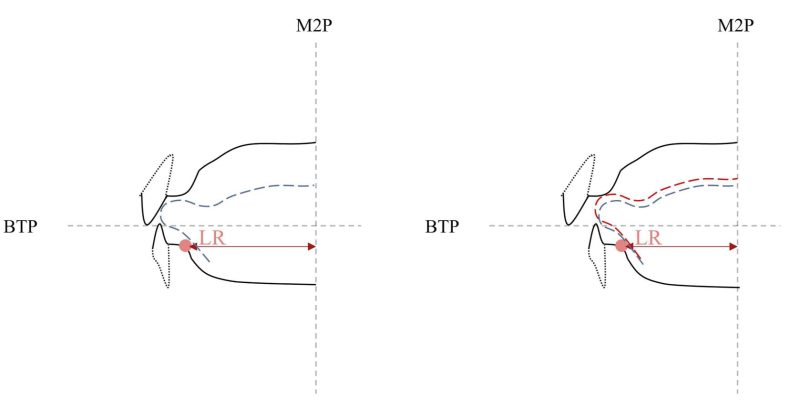
Should these anatomical variables hold under replication, we further propose a possible mechanistic explanation for the tendency to use alveolar substitutions, relating to the length and/or forwardness of the lower jaw (slMDepth). The left image of Figure 10 shows an “ideal” anterior vocal tract configuration, from which dental fricatives can be produced relatively effortlessly with the tongue tip/blade close behind the upper incisors. By contrast, a slightly more retracted/shorter lower jaw (right image) may “bias” towards a more posterior place of articulation, from dental to alveolar. Additionally, it is also possible that the lower incisors do not provide enough clearance for the production of dental fricatives (with a dental place of articulation), biasing towards an alveolar stop production.
Interestingly, Dediu et al. (2019) show, using Canonical Variate Analysis (CVA) and Procrustes ANOVA with permutation on a superset of the same data used here, that the anatomy of the anterior vocal tract does vary between sexes and broad ethno-linguistic groups. Importantly, however, this variation is continuous and small, there are lots of overlaps and many “miss-classified” participants, and it only becomes apparent when using highly multivariate datasets.
In sum, dental fricatives are rare due to a variety of factors. They are difficult to produce in both L1 and L2 acquisition. They are difficult to perceive in L2 and in borrowing situations due to their easily confusable acoustic properties. Despite the assumption that they should be the common result of lenition, very few attested sound changes result in dental fricatives (Kümmel 2007). They are lost frequently and typically merge with other phonemes (Kümmel 2007). Their world-wide synchronic distribution suggests that although they may arise relatively easily (e.g., /θ/ spontaneously replaced /s/ in Spanish in the middle of the 17th century (Penny 2002); although more recent research suggests that the dental fricatives came into existence in the 1500s (Mackenzie 2022)), they are unstable and tend to either be not fully phonologized or quickly lost (e.g., they did not spread to Spanish varieties in the Americas). This suggests that their phonetic properties play a role in their instability and in why they pattern sporadically geographically and genealogically. As pointed out above, dental fricatives are easily confused with other sounds, particularly non-sibilant labiodental fricatives [f, v] and alveolar or dental stops [t, d]. They are rarely borrowed correctly (Grossman et al. 2020) and pidgins and creoles almost never inherit them from their lexifiers (Michaelis et al. 2013). Finally, our data suggests that tiny, continuous and overlapping patterns of variation in the anatomy of the anterior oral vocal tract (Dediu et al. 2019; Dediu and Moisik 2019) may help explain their instability and geographic patterning, but it would represent only one weak influence among many others and much more evidence is needed before drawing causal conclusions of this nature (Blasi et al. 2019; Dediu et al. 2017; Josserand et al. 2021; Moisik and Dediu 2017). Thus, dental fricatives are rare speech sounds for a multitude of reasons touching upon their articulation, acoustics and confusability with other speech sounds.
Acknowledgments & supplementary information
D.D. and S.R.M. were funded by the Netherlands Organization for Scientific Research (NWO) VIDI grant 276-70-022 (2012-2017) during the design and collection of the data. D.D. was also funded by a European Institutes for Advanced Study (EURIAS) fellowship program and an IDEXLYON (16-IDEX-0005) fellowship grant (2018-2021) during the initial analysis of the data. S.M. was funded by the Swiss National Science Foundation (Grant No. PCEFP1_186841). D.D. thanks the Collegium de Lyon, the ASLAN project (ANR-10-LABX-0081) of the Université de Lyon, for its financial support within the French program “Investments for the Future” operated by the National Research Agency (ANR), the Catalan Institute for Research and Advanced Studies (ICREA) and the University of Barcelona, Barcelona, Spain. We wish to thank the organizers of the Annual Symposium of the Words, Bones, Genes and Tools project, 3-4 December 2021 at the University of Tübingen, Germany, and to Gerhard Jäger in particular. We also wish to thank Gerhard Jäger and the anonymous reviewers for their very constructive feedback on an earlier version of this paper.
Author Contributions: D.D., S.R.M. and S.M. designed research. S.M. collected data and performed typological and evolutionary analyses. S.R.M. and D.D. designed ArtiVarK study. S.R.M. collected ArtiVarK data. J.L., S.R.M. and D.D. analyzed ArtiVarK data. S.M. wrote report on typology and evolution. J.L., S.R.M. and D.D. wrote report on articulatory performance. All authors drafted the paper. All authors contributed to, read, and approved the paper.
Data and code needed to reproduce these results are available under open source licenses in three GitHub repositories: bambooforest/interdentals (cross-linguistic analyses), ScottMoisik/DentalFricGit (experimental approaches), and ddediu/the (the paper itself). Ethics Statement: The intra-oral scanning and acoustic data are part of the ArtivarK project, which is covered by the ethics approval 45659.091.14 (1 June 2015), Donders Center for Brain, Cognition and Behaviour, Nijmegen. For a full description, please see the Supplementary file 1 of Dediu & Moisik (2019) hosted at doi:10.5281/zenodo.1480427.
References
Altenberg, E. P., and R. M. Vago. 1983. Theoretical Implications of an Error Analysis of Second Language Phonology Production. Language Learning 33(4): 427–447. https://doi.org/10.1111/j.1467-1770.1983.tb00943.x.
Aoyama, K., J. E. Flege, S. G. Guion, R. Akahane-Yamada, and T. Yamada. 2004. Perceived phonetic dissimilarity and L2 speech learning: The case of Japanese /r/ and English /l/ and /r/. Journal of Phonetics 32(2): 233–250. https://doi.org/https://doi.org/10.1016/S0095-4470(03)00036-6.
Ball, M. J., S. J. Howard, and K. Miller. 2018. Revisions to the extIPA chart. Journal of the International Phonetic Association 48(2): 155–164. https://doi.org/10.1017/S0025100317000147.
Bates, D., M. Mächler, B. Bolker, and S. Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67(1): 1–48. https://doi.org/10.18637/jss.v067.i01.
Best, C. T. 1994. The emergence of native-language phonological influences in infants: A perceptual assimilation model. Dev. Speech Percept. 167: 233–277.
Best, C. T., G. W. McRoberts, and E. Goodell. 2001. Discrimination of non-native consonant contrasts varying in perceptual assimilation to the listener’s native phonological system. The Journal of the Acoustical Society of America 109(2): 775–794. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2777975/.
Bhatt, R. M. 1995. Prescriptivism, creativity and world englishes. World Englishes 14: 247–259.
Blasi, D. E., S. Moran, S. R. Moisik, P. Widmer, D. Dediu, and B. Bickel. 2019. Human sound systems are shaped by post-Neolithic changes in bite configuration. Science 363(6432): eaav3218. https://doi.org/10.1126/science.aav3218.
Blevins, J. 2006. New Perspectives on English Sound Patterns: “Natural” and “Unnatural” in Evolutionary Phonology. Journal of English Linguistics 34(1): 6–25. https://doi.org/10.1177/0075424206287585.
Boersma, P., and D. Weenink. 2001. PRAAT, a system for doing phonetics by computer. Glot International 5: 341–345.
Bolton, K., and H. Kwok. 1990. The dynamics of the Hong Kong accent: Social identity and sociolinguistic description. Journal of Asian Pacific Communication (Multilingual Matters) 1(1): 147–172.
Brannen, K. J. 2002. The role of perception in differential substitution. Canadian Journal of Linguistics 47: 1–46. https://doi.org/10.1017/S0008413100018004.
Brannen, K. J. 2011. The perception and production of interdental fricatives in second language acquisition (PhD thesis). McGill University.
Brunner, J., S. Fuchs, and P. Perrier 2009. On the relationship between palate shape and articulatory behavior. The Journal of the Acoustical Society of America 125(6): 3936–3949. https://doi.org/10.1121/1.3125313.
Bürkner, P.-C. 2021. Bayesian item response modeling in R with brms and Stan. Journal of Statistical Software 100(5): 1–54. https://doi.org/10.18637/jss.v100.i05.
Chang, W., C. Cathcart, D. Hall, and A. Garrett. 2015. Ancestry-constrained phylogenetic analysis supports Indo-European steppe hypothesis. Language 91: 194–244. https://doi.org/10.1353/lan.2015.0005.
Cornwell, S., and Y. Rafat. 2017. English interdental fricative production in dutch heritage speakers living in canada. Ilha Do Desterro 70: 95–115. https://doi.org/10.5007/2175-8026.2017v70n3p95.
Cutler, A., A. Weber, R. Smits, and N. Cooper. 2004. Patterns of English phoneme confusions by native and non-native listeners. The Journal of the Acoustical Society of America 116(6): 3668–3678. https://doi.org/10.1121/1.1810292.
Dediu, D., R. Janssen, and S. R. Moisik. 2017. Language is not isolated from its wider environment: Vocal tract influences on the evolution of speech and language. Language and Communication 54: 9–20. https://doi.org/10.1016/j.langcom.2016.10.002.
Dediu, D., R. Janssen, and S. R. Moisik. 2019. Weak biases emerging from vocal tract anatomy shape the repeated transmission of vowels. Nature Human Behaviour 3: 1107–1115. https://doi.org/10.1038/s41562-019-0663-x.
Dediu, D., and S. R. Moisik. 2019. Pushes and pulls from below: Anatomical variation, articulation and sound change. Glossa: A Journal of General Linguistics 4(1): 7. https://doi.org/10.5334/gjgl.646.
Deterding, D. 2006. The pronunciation of English by speakers from China. English World-Wide 27(2): 175–198. https://doi.org/10.1075/eww.27.2.04det.
Deterding, D., J. Wong, and A. Kirkpatrick. 2008. The pronunciation of Hong Kong English. English World-Wide 29(2): 148–175. https://doi.org/10.1075/eww.29.2.03det.
Dickerson, W., and L. Dickerson. 1977. Interlanguage phonology: Current research and future directions. In The notions of simplification, interlanguages and pidgins, ed. by S. P. Corder and E. Roulet, pp. 18–30. Faculté des Lettres.
Dunn, M., S. C. Levinson, E. Lindström, G. Reesink, and A. Terrill. 2008. Structural Phylogeny in Historical Linguistics: Methodological Explorations Applied in Island Melanesia. Language 84: 710–759.
Eisen, E. 2019. The Typology of Phonological Segment Borrowing (MA in linguistics, Hebrew University of Jerusalem). Hebrew University of Jerusalem, Jerusalem. https://doi.org/10.13140/RG.2.2.36245.55529.
Flege, J. E. 1986. Effects of equivalence classification on the production of foreign language speech sounds. In Sound patterns in second language acquisition, ed. by A. James and J. Leather, pp. 9–40. De Gruyter Mouton. https://doi.org/doi:10.1515/9783110878486-003.
Flege, J. E. 1995. Second-language speech learning: Theory, findings, and problems. In Speech perception and linguistic experience: Issues in cross-language research, ed. by SW. Strange, pp. 233–277. York Press.
Flege, J. E. 2003. Assessing constraints on second-language segmental production and perception. In Phonetics and phonology in language comprehension and production: Differences and similarities, ed. by N. O. Schiller and A. S. Meyer, pp. 319–358. De Gruyter Mouton. https://doi.org/doi:10.1515/9783110895094.319.
Fry, D. B. 1979. The Physics of Speech. Cambridge University Press.
Gatbonton, E. 1978. Patterned Phonetic Variability in Second-Language Speech: A Gradual Diffusion Model. The Canadian Modern Language Review 34(3): 335–347. https://doi.org/10.3138/cmlr.34.3.335.
Gick, B., B. Allen, F. Roewer-Després, and I. Stavness. 2017. Speaking Tongues Are Actively Braced. Journal of Speech, Language, and Hearing Research 60(3): 494–506. https://doi.org/10.1044/2016_JSLHR-S-15-0141.
Graeppi, C., and A. Leemann. 2019. Between-speaker variation in english learners’ realisations of dental fricatives. In Proceedings of the 19th international congress of phonetic sciences, melbourne, australia 2019 (ICPhS2019), ed. by S. Calhoun, P. Escudero, M. Tabain, P. Warren, pp. 974–978.
Grossman, E., E. Eisen, D. Nikolaev, and S. Moran 2020. Segbo-db/segbo: v0.0.0. Online: https://doi.org/10.5281/zenodo.3633918; Zenodo. https://doi.org/10.5281/zenodo.3633918.
Hammarström, H., R. Forkel, M. Haspelmath, and S. Bank. 2020. Glottolog 4.2.1. Jena: Max Planck Institute for the Science of Human History. https://doi.org/10.5281/zenodo.3754591.
Hancin-Bhatt, B. 1994. Segment transfer: A consequence of a dynamic system. Second Language Research 10(3): 241–269. Retrieved from https://www.jstor.org/stable/43104496.
Hanulíková, A., and A. Weber. 2010. Production of english interdental fricatives by dutch, german, and english speakers. In Proceedings of the 6th international symposium on the acquisition of second language speech, new sounds 2010, poznań, poland, 1-3 may 2010, ed. by K. Dziubalska-Kołaczyk, M. Wrembel, M. Kul, pp. 173–178. Poznan: Adam Mickie-wicz Universit.
Hockett, C. F. 1985. Distinguished Lecture: F. American Anthropologist 87(2): 263–281. Retrieved from www.jstor.org/stable/678561.
Huelsenbeck, J. P., R. Nielsen, and J. P. Bollback. 2003. Stochastic mapping of morphological characters. Systematic Biology 52(2): 131–158. https://doi.org/10.1080/10635150390192780.
Jongman, A., R. Wayland, and S. Wong. 2000. Acoustic characteristics of English fricatives. The Journal of the Acoustical Society of America 108(3): 1252–1263. https://doi.org/10.1121/1.1288413.
Josserand, M., E. Meeussen, A. Majid, and D. Dediu. 2021. Environment and culture shape both the colour lexicon and the genetics of colour perception. Scientific Reports 11(1): 19095. https://doi.org/10.1038/s41598-021-98550-3.
Kirby, K. R., R. D. Gray, S. J. Greenhill, F. M. Jordan, S. Gomes-Ng, H.-J. Bibiko, et al. 2016. D-PLACE: A global database of cultural, linguistic and environmental diversity. PLoS ONE 11(7): e0158391.
Kümmel, M. 2007. Konsonantenwandel: Bausteine zu einer Typologie des Lautwandels und ihre Konsequenzen für die vergleichende Rekonstruktion. Reichert Verlag.
Ladefoged, P. 1990. Some reflections on the IPA. Journal of Phonetics 18(3): 335–346. https://doi.org/https://doi.org/10.1016/S0095-4470(19)30378-X.
Ladefoged, P., and K. Johnson. 2010. A Course in Phonetics. Cengage Learning.
Ladefoged, P., and I. Maddieson. 1996. The sounds of the world’s languages. Cambridge, UK: Blackwell.
Laitman, J. T., D. M. Noden, and T. R. Van De Water. 2014. Formation of the larynx: From hox genes to critical periods. In Diagnosis and treatment of voice disorders, ed. by J. S. Rubin, R. T. Sataloff, and G. S. Korovin. Plural Publishing.
Mackenzie, I. 2022. The genesis of spanish /θ/: A revised model. Languages 7(3). https://doi.org/10.3390/languages7030191.
Maddieson, I. 1984. Patterns of sounds. Cambridge: Cambridge University Press.
Maniwa, K., A. Jongman, and T. Wade. 2009. Acoustic characteristics of clearly spoken english fricatives. The Journal of the Acoustical Society of America 125(6): 3962–3973.
Marsico, E., S. Flavier, A. Verkerk, and S. Moran. 2018. BDPROTO: A database of phonological inventories from ancient and reconstructed languages. Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018).
McHugh, M. L. 2012. Interrater reliability: The kappa statistic. Biochemia Medica 22(3): 276–282. https://doi.org/10.11613/BM.2012.031.
Michaelis, S. M., P. Maurer, M. Haspelmath, and M. Huber. 2013. APiCS online. Leipzig: Max Planck Institute for Evolutionary Anthropology. Retrieved from https://apics-online.info/.
Mielke, J., K. S. Olson, A. Baker, and D. Archangeli. 2011. Articulation of the kagayanen interdental approximant: An ultrasound study. Journal of Phonetics 39(3): 403–412.
Moisik, S. R., and D. Dediu. 2017. Anatomical biasing and clicks: Evidence from biomechanical modeling. Journal of Language Evolution 2(1): 37–51. https://doi.org/doi:10.1093/jole/lzx004.
Monk, B., and A. Burak. 2001. Russian speakers. In Learner english: A teacher’s guide to interference and other problems, ed. by M. Swan, and B. Smith, pp. 145–161. Cambridge University Press.
Moorthy, S. M., and D. Deterding. 2000. Three or tree? Dental fricatives in the speech of educated Singaporeans. In The English language in Singapore: Research on pronunciation, ed. by A. Brown, D. Deterding, and E. L. Low, pp. 76–83. Singapore: Singapore Association for Applied Linguistics.
Moran, S., E. Grossman, and A. Verkerk. 2020. Investigating diachronic trends in phonological inventories using BDPROTO. Language Resources and Evaluation. https://doi.org/10.1007/s10579-019-09483-3.
Moran, S., N. A. Lester, and E. Grossman. 2021. Inferring recent evolutionary changes in speech sounds. Philosophical Transactions of the Royal Society B 376(1824): 20200198.
Moran, S., and D. McCloy. 2019. PHOIBLE 2.0. Jena: Max Planck Institute for the Science of Human History. https://doi.org/10.5281/zenodo.2562766.
Narasimhan, S. 2001. Speakers of dravidian languages: Tamil, malayalam, kannada, telugu. In Learner english: A teacher’s guide to interference and other problems, ed. by M. Swan, and B. Smith, pp. 244–250. Cambridge University Press.
Narayanan, S. S., A. A. Alwan, and K. Haker. 1995. An articulatory study of fricative consonants using magnetic resonance imaging. The Journal of the Acoustical Society of America 98(3): 1325–1347. https://doi.org/10.1121/1.413469.
Nichols, J. 2017. Diversity and stability in language. The Handbook of Historical Linguistics: 283–310.
Nielsen, R. 2002. Mapping mutations on phylogenies. Systematic Biology 51: 729–732. https://doi.org/10.1080/10635150290102393.
Olson, K. S., J. Mielke, J. Sanicas-Daguman, C. J. Pebley, and H. J. Paterson. 2010. The phonetic status of the (inter) dental approximant. Journal of the International Phonetic Association 40(2): 199–215.
Paradis, C., and D. LaCharité. 2012. The influence of attitude on the treatment of interdentals in loanwords: Ill-performed importations. Catalan Journal of Linguistics 11: 97–126. https://doi.org/10.5565/rev/catjl.12.
Penny, R. 2002. A History of the Spanish Language (2nd ed.). Cambridge University Press.
Picard, M. 2002. The differential substitution of English /θ ð/ in French: The case against underspecification in L2 phonology. Lingvisticæ Investigationes 25(1): 87–96. https://doi.org/10.1075/li.25.1.07pic.
R Core Team. 2021. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from https://www.R-project.org/.
Rau, D. V., H.-H. A. Chang, and E. E. Tarone. 2009. Think or Sink: Chinese Learners’ Acquisition of the English Voiceless Interdental Fricative. Language Learning 59(3): 581–621. https://doi.org/10.1111/j.1467-9922.2009.00518.x.
Reis, M. S. 2006. The perception and production of English interdental fricatives by Brazilian EFL learners (Master’s thesis, Universidade Federal de Santa Catarina). Universidade Federal de Santa Catarina, Florianópolis, Brazil. Retrieved from https://repositorio.ufsc.br/xmlui/handle/123456789/89154.
Revell, L. J. 2012. phytools: An R package for phylogenetic comparative biology (and other things). Methods in Ecology and Evolution 3(2): 217–223.
Runte, C., M. Lawerino, D. Dirksen, F. Bollmann, A. Lamprecht-Dinnesen, and E. Seifert. 2001. The influence of maxillary central incisor position in complete dentures on /s/ sound production. The Journal of Prosthetic Dentistry 85(5): 485–495. https://doi.org/10.1067/mpr.2001.114448.
Sander, E. K. 1972. When are speech sounds learned? Journal of Speech and Hearing Disorders 37(1): 55–63.
Shackle, C. 2001. Speakers of south asian languages. In Learner english: A teacher’s guide to interference and other problems. 2nd ed., ed. by M. Swan, and B. Smith, pp. 227–243. Cambridge University Press. https://doi.org/10.1017/CBO9780511667121.016.
Strevens, P. 1960. Spectra of Fricative Noise in Human Speech. Language and Speech 3(1): 32–49. https://doi.org/10.1177/002383096000300105.
Swan, M. 2001. German speakers. In Learner english: A teacher’s guide to interference and other problems, ed. by M. Swan, and B. Smith, pp. 30–41. Cambridge University Press.
Syed, N. A. 2013. Acquisition of english dental fricatives by pakistani learners. Newcastle Working Papers in Linguistics 59.
Teasdale, A. 1997. On the differential substitution of english [θ] a phonetic approach. Calgary Working Papers in Linguistics 19: 71–92. https://doi.org/10.11575/PRISM/10182.
Thomason, S. G., and T. Kaufman. 1988. Language contact, creolization, and genetic linguistics. University of California Press: Berkeley.
Thompson, I. 2001. Japanese speakers. In Learner English: A teacher’s guide to interference and other problems, ed. by M. Swan, and B. Smith, pp. 296–309. Cambridge University Press.
Weinberger, S. H. 1997. Minimal segments in second language phonology. In Minimal segments in second language phonology, pp. 263–312. De Gruyter Mouton. https://doi.org/10.1515/9783110882933.263.
Wester, F., D. Gilbers, and E. Lowie. 2007. Substitution of dental fricatives in English by Dutch L2 speakers. Language Sciences 29(2-3): 477–491. https://doi.org/10.1016/j.langsci.2006.12.029.
Wiley, D. F. 2007. Landmark. California, USA: Institute for Data Analysis; Visualization (IDAV) group at the University of California, Davis. Retrieved from https://www.cs.ucdavis.edu/~amenta/LandmarkDoc_v3_b6.pdf.
Wright, R. 2004. A review of perceptual cues and cue robustness. In Phonetically based phonology, ed. by B. Hayes, R. Kirchner, and D. Steriade, pp. 34–57. Cambridge University Press.
Xie, Y., J. J. Allaire, and G. Grolemund. 2018. R markdown: The definitive guide. Boca Raton, Florida: Chapman; Hall/CRC. Retrieved from https://bookdown.org/yihui/rmarkdown.
Zhang, M., S. Yan, W. Pan, and L. Jin. 2019. Phylogenetic evidence for sino-tibetan origin in northern china in the late neolithic. Nature 569(7754): 112–115. https://doi.org/10.1038/s41586-019-1153-z.
Appendix: Landmarks & anatomical measures
Here we present the landmarks and anatomical measures used in this
study.*
Landmarks:
TS = point on the palate roof near the transverse suture and corresponding to the plane containing the second molar landmarks and orthogonal to BTP;
PH = peak height of the palate roof;
UR = superior (maxillary) midsagittal alveolar ridge inflection point;
LR = inferior (mandibular) midsagittal alveolar ridge inflection point;
UM = lingual gingival margin of the upper (maxillary) incisors;
UE = incisal edge of the upper (maxillary) incisors;
LE = incisal edge of the lower (mandibular) incisors;
M2 = paired landmark for the central point of the occlusal surface of the second molar (or closest approximation if molar is missing).
Conventions: the bite plane (BTP) was established with reference to the second molars in occlusal position and the central incisors judging from their sagittal profile. Where mentioned, a regression line refers to the line of best fit between the z-components (front-back; anterior-posterior) and y-components (up-down; superior-inferior) of 3D intraoral scan vertices drawn from within 0.5 mm on either side of the midsagittal
plane. Some measurements are defined with reference to projections of a landmark onto a given plane. In addition to BTP, there is also the peak height plane (PHP), which refers to the horizontal plane tangent to PH and the coronal plane intersecting the second molar landmarks (M2P).
Anatomical measures:


Other variables:
